

Chaos Engineering: The Batman🦇of CloudNative

20 🧑💻 Lens IDE Ambassador🥑| Cloud-Native ☁️, SRE➰ Open Source, ML & LLMs🤖 & MERN Stack🌐 | Tech Blogger⌨️ Postman🚀API Student Expert
We all have read from childhood that "Prevention is better than cure" which applies to tech as well, instead of looking around for the solutions to the various breakdowns and faults at the time our system got down, it's better to have it check-up with regular drills to test out its efficiency and take steps to increase it effortlessly.
Several projects and companies have been making efforts combined to make this task go as smoothly as possible, well documented as well to make it popular amongst newbies and encourage more companies to include it in their production to make their architecture more strong and unbeatable by various methods which we will be getting to know in this blog.

Introduction
Just like Batman🦇, it shows up in various time stamps to check out for any problems in the system or production and points them out to make them get solved without having to deal with them at the main time of carnival i.e. the hot season of the highest traffic on the application.
Chaos engineering is the discipline of experimenting on a system in order to build confidence in the system's capability to withstand turbulent conditions in production.
Calculating how much confidence we can have in the interconnected complex systems that are put into the production environment requires operational readiness metrics. Operational readiness can be evaluated using chaos engineering simulations supported by Kubernetes infrastructure in big data. Solutions for the operational readiness of a platform stand for strengthening the backup, restore network file transfer, failover capabilities and overall security.
Working🐒
The real way to verify high availability is to kill one or more of your cluster nodes and see what happens. The same applies to the high availability of your Kubernetes Pods and applications.
Doing this manually is time-consuming, and consumes extra resources and staff as well if you don't know much about it and without realizing it you may be unconsciously sparing resources that you know are application-critical. The best way to make it seamless and efficient is by making it automated.

This kind of automated, random interference with production services is sometimes known as Chaos Monkey testing, after the tool of the same name developed by Netflix to test its infrastructure, which happens to have an interesting story for naming it Chaos Monkey:
Imagine a monkey entering a data center, these farms of servers that host all the critical functions of our online activities. The monkey randomly rips cables and destroys devices... The challenge for IT managers is to design the information system they are responsible for so that it can work despite these monkeys, which no one ever knows when they arrive and what they will destroy.
Apart from Chaos Monkey itself, which terminates random cloud servers, the Netflix Simian Army also includes other chaos engineering tools such as Latency Monkey, which introduces communication delays to simulate network issues, Security Monkey, which looks for known vulnerabilities, and Chaos Gorilla, which drops a whole AWS availability zone.
Problems Faced🙈🙈

Many systems are too big, complex, and cost-prohibitive to clone. Imagine trying to spin up a copy of Facebook for testing with its multiple, globally distributed data centers. The unpredictability of user traffic makes it impossible to mock; even if you could perfectly reproduce yesterday’s traffic, you still can’t predict tomorrow’s. Only production is production.
It’s also important to note that your chaos experiments, to be most useful, need to be automated and continuous. It’s no good doing it once and deciding that your system is reliable forever.
The whole point of automating your chaos experiments is so that you can run them again and again to build trust and confidence in your system. Not just surfacing new weaknesses, but also ensuring that you’ve overcome a weakness in the first place.
There are various tools that can be helpful in automatically chaos engineering your cluster.
Tools:
Chaoskube

chaoskube randomly kills Pods in your cluster. By default, it operates in dry-run mode, which shows you what it would have done, but doesn’t actually terminate anything. You can configure chaoskube to include or exclude Pods based on labels, annotations, and namespaces, and to avoid certain time periods or dates By default, though, it will potentially kill any Pod in any namespace, including Kubernetes system Pods, and even chaoskube itself.
Once you’re happy with your chaoskube filter configuration, you can disable dry-run mode and let it do its work. chaoskube is simple to install and set up, and it’s an ideal tool for getting started with chaos engineering.
Well that was an overview explanation of what it do let's go a bit further deep into it:
chaoskube allows filtering target pods by namespaces, labels, annotations and age as well as excluding certain weekdays, times of day and days of the year from chaos.
You can install chaoskube with Helm. Follow Helm's Quickstart Guide and then install the chaoskube chart.
$ helm repo add chaoskube https://linki.github.io/chaoskube/
$ helm install chaoskube chaoskube/chaoskube --atomic --namespace=chaoskube --create-namespace
Configuration:
By default, chaoskube will be friendly and not kill anything. When you validated your target cluster you may disable dry-run mode by passing the flag --no-dry-run. You can also specify a more aggressive interval and other supported flags for your deployment.
If you're running in a Kubernetes cluster and want to target the same cluster then this is all you need to do.
If you want to target a different cluster or want to run it locally specify your cluster via the --master flag or provide a valid kubeconfig via the --kubeconfig flag. By default, it uses your standard kubeconfig path in your home. That means, whatever the current context in there will be targeted.
If you want to increase or decrease the amount of chaos change the interval between killings with the --interval flag. Alternatively, you can increase the number of replicas of your chaoskube deployment.
Remember that chaoskube by default kills any pod in all your namespaces, including system pods and itself.
chaoskube provides a simple HTTP endpoint that can be used to check that it is running. This can be used for Kubernetes liveness and readiness probes. By default, this listens on port 8080. To disable, pass --metrics-address="" to chaoskube.
To know more about their projects reach out to their github page:
https://github.com/linki/chaoskube
Kube-monkey

kube-monkey is an implementation of Netflix's Chaos Monkey for Kubernetes clusters. It randomly deletes Kubernetes (k8s) pods in the cluster encouraging and validating the development of failure-resilient services.
kube-monkey runs at a pre-configured hour (run_hour, defaults to 8 am) on weekdays, and builds a schedule of deployments that will face a random Pod death sometime during the same day. The time-range during the day when the random pod Death might occur is configurable and defaults to 10 am to 4 pm.
kube-monkey can be configured with a list of namespaces to blacklist (any deployments within a blacklisted namespace will not be touched) To disable the blacklist provide [""] in the blacklisted_namespaces config.param.
This means that you can add kube-monkey testing to specific apps or services during their development, and set different levels of frequency and aggression depending on the service. For example, the following annotation on a Pod will set a mean time between failures (MTBF) of two days:
kube-monkey/mtbf: 2
The kill-mode annotation lets you specify how many of a Deployment’s Pods will be killed, or a maximum percentage. The following annotations will kill up to 50% of the Pods in the targeted Deployment:
kube-monkey/kill-mode: "random-max-percent"
kube-monkey/kill-value: 50
How kube-monkey works
Scheduling time
Scheduling happens once a day on Weekdays - this is when a schedule for terminations for the current day is generated. During scheduling, kube-monkey will:
Generate a list of eligible k8s apps (k8s apps that have opted-in and are not blacklisted, if specified, and are whitelisted, if specified)
For each eligible k8s app, flip a biased coin (bias determined by kube-monkey/mtbf) to determine if a pod for that k8s app should be killed today
For each victim, calculate a random time when a pod will be killed Termination time This is the randomly generated time during the day when a victim k8s app will have a pod killed.
Terminating time
This is the randomly generated time during the day when a victim k8s app will have a pod killed. At termination time, kube-monkey will:
Check if the k8s app is still eligible (has not opted-out or been blacklisted or removed from the whitelist since scheduling)
Check if the k8s app has updated kill-mode and kill-value
Depending on kill-mode and kill-value, execute pods
To know more about their projects reach out to their github page:
https://github.com/asobti/kube-monkey
Powerful Seal

PowerfulSeal injects failure into your Kubernetes clusters, so that you can detect problems as early as possible. It allows for writing scenarios describing complete chaos experiments.
Modes
PowerfulSeal works in several modes:
Autonomous mode reads a policy file, that can contain any number of scenarios. It will continuously execute the desired scenarios and produce metrics. This is designed for when you know what kind of failure you’d like to inject into your cluster.
Interactive mode is designed to allow you to discover your cluster’s components and manually break things to see what happens. It has fewer features than the autonomous mode and should be used during the initial phase of planning a chaos experiment.
Label mode allows you to specify which pods to kill with a small number of options by adding seal/ labels to pods. This is a more imperative alternative to autonomous mode.
To know more about their projects reach out to their github page:
https://github.com/powerfulseal/powerfulseal
Litmus Chaos

LitmusChaos is an open source Chaos Engineering platform that enables teams to identify weaknesses & potential outages in infrastructures by inducing chaos tests in a controlled way. Developers & SREs can practice Chaos Engineering with LitmusChaos as it is easy to use, based on modern Chaos Engineering principles & community collaborated. It is 100% open source & a CNCF project.
LitmusChaos takes a cloud-native approach to create, manage and monitor chaos. The platform itself runs as a set of microservices and uses Kubernetes custom resources to define the chaos intent, as well as the steady-state hypothesis.
LitmusChaos is a highly Open-Source Project having a lot of projects being opened to the newbies to contribute to and show their contribution to the community and get more opportunities from the various companies and organizations managing with the same domain and applications, which most of the big projects and companies have been doing to make their architecture more reliable, flexible, strong and unbreakable. It also allows a lot of newbies to get engaged with ChaosEngineering.
LitmusChaos also participates in a lot of events like Google Summer of Code, Hacktoberfest and a lot more to give people some hands-on experience in chaos Engineering by a lot of methods like by Fixing Bugs, Making Unit tests, Automation applications, architecture and lot more features and applications as well.
At a high level, Litmus comprises:
Chaos Control Plane: A centralized chaos management tool called chaos-center, which helps construct, schedule and visualize Litmus chaos workflows
Chaos Execution Plane Services: Made up of a chaos agent and multiple operators that execute & monitor the experiment within a defined target Kubernetes environment.
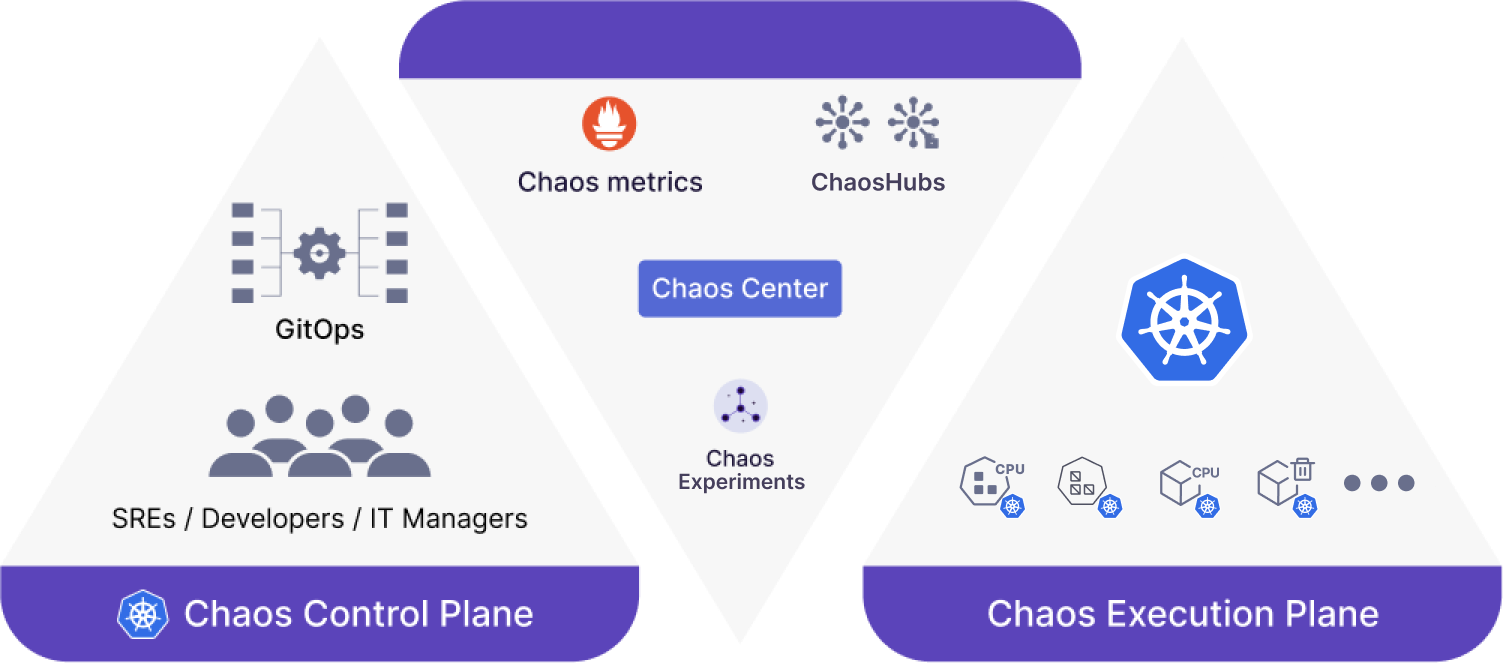
At the heart of the platform are the following chaos custom resources:
ChaosExperiment: A resource to group the configuration parameters of a particular fault. ChaosExperiment CRs are essentially installable templates that describe the library carrying out the fault, indicate permissions needed to run it & the defaults it will operate with. Through the ChaosExperiment, Litmus supports BYOC (bring-your-own-chaos) that helps integrate (optional) any third-party tooling to perform the fault injection.
ChaosEngine: A resource to link a Kubernetes application workload/service, node or an infra component to a fault described by the ChaosExperiment. It also provides options to tune the run properties and specify the steady state validation constraints using 'probes'. ChaosEngine is watched by the Chaos-Operator, which reconciles it (triggers experiment execution) via runners.
The ChaosExperiment & ChaosEngine CRs are embedded within a Workflow object that can string together one or more experiments in a desired order.
- ChaosResult: A resource to hold the results of the experiment run. It provides details of the success of each validation constraint, the revert/rollback status of the fault as well as a verdict. The Chaos-exporter reads the results and exposes information as prometheus metrics. ChaosResults are especially useful during automated runs.
Use cases
For Developers: To run chaos experiments during application development as an extension of unit testing or integration testing.
For CI/CD pipeline builders: To run chaos as a pipeline stage to find bugs when the application is subjected to fail paths in a pipeline.
For SREs: To plan and schedule chaos experiments into the application and/or surrounding infrastructure. This practice identifies the weaknesses in the deployment system and increases resilience.
For more information about this amazing community and project reach out to their github page:
https://github.com/litmuschaos
Hope you get to find a lot of knowledge and data, you came to read this blog. Soon, I will be writing and releasing more blogs about chaos engineering and some explanations and tutorials about how you can contribute to ChaosEngineering and how can it be turned into the most efficient and useful skill.

If you like my Article then please react to it and connect with me on Twitter if you are also a tech enthusiast. I would love to collaborate with people and share the experience of tech😄😄.
My Twitter Profile:




